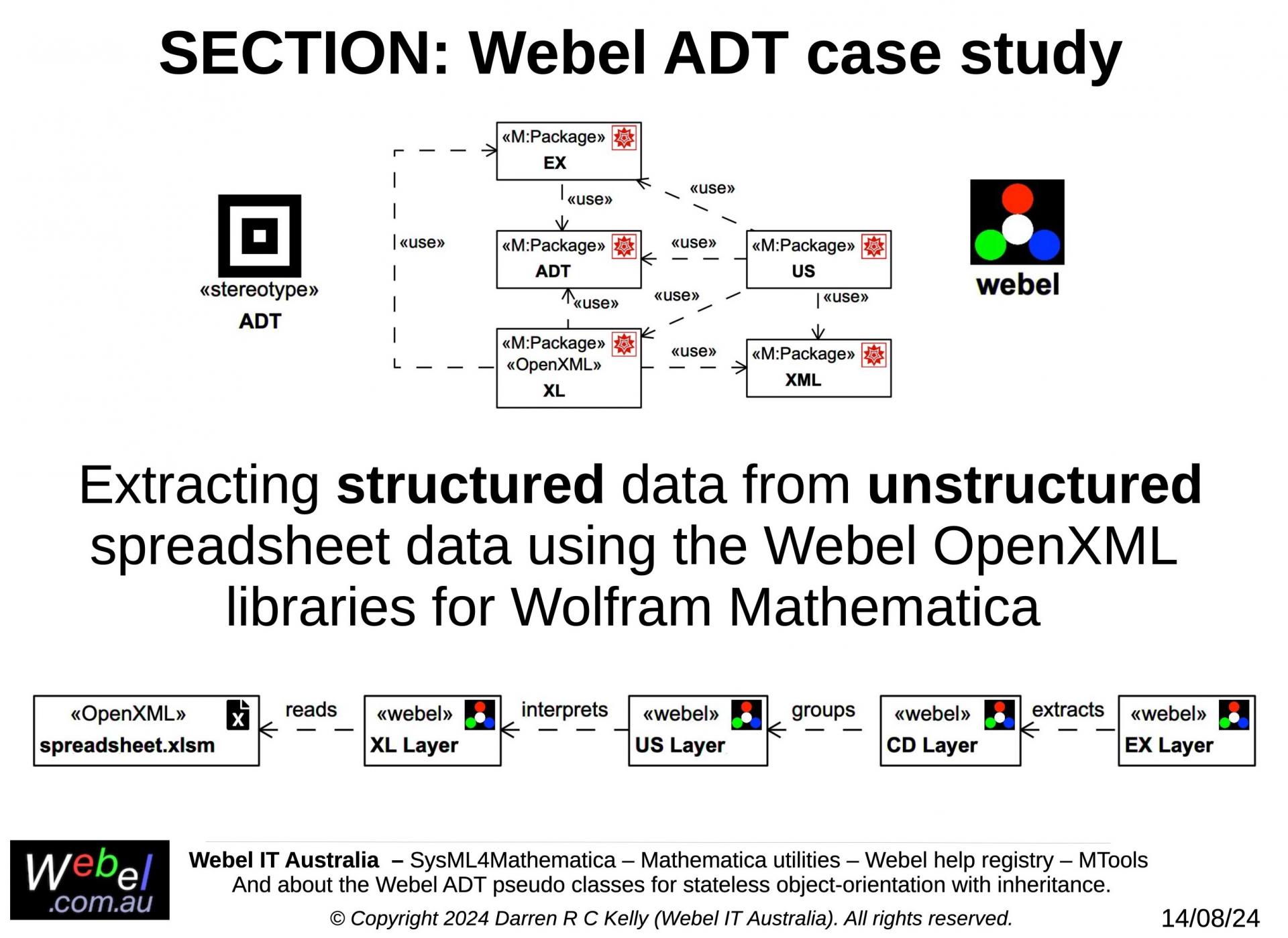
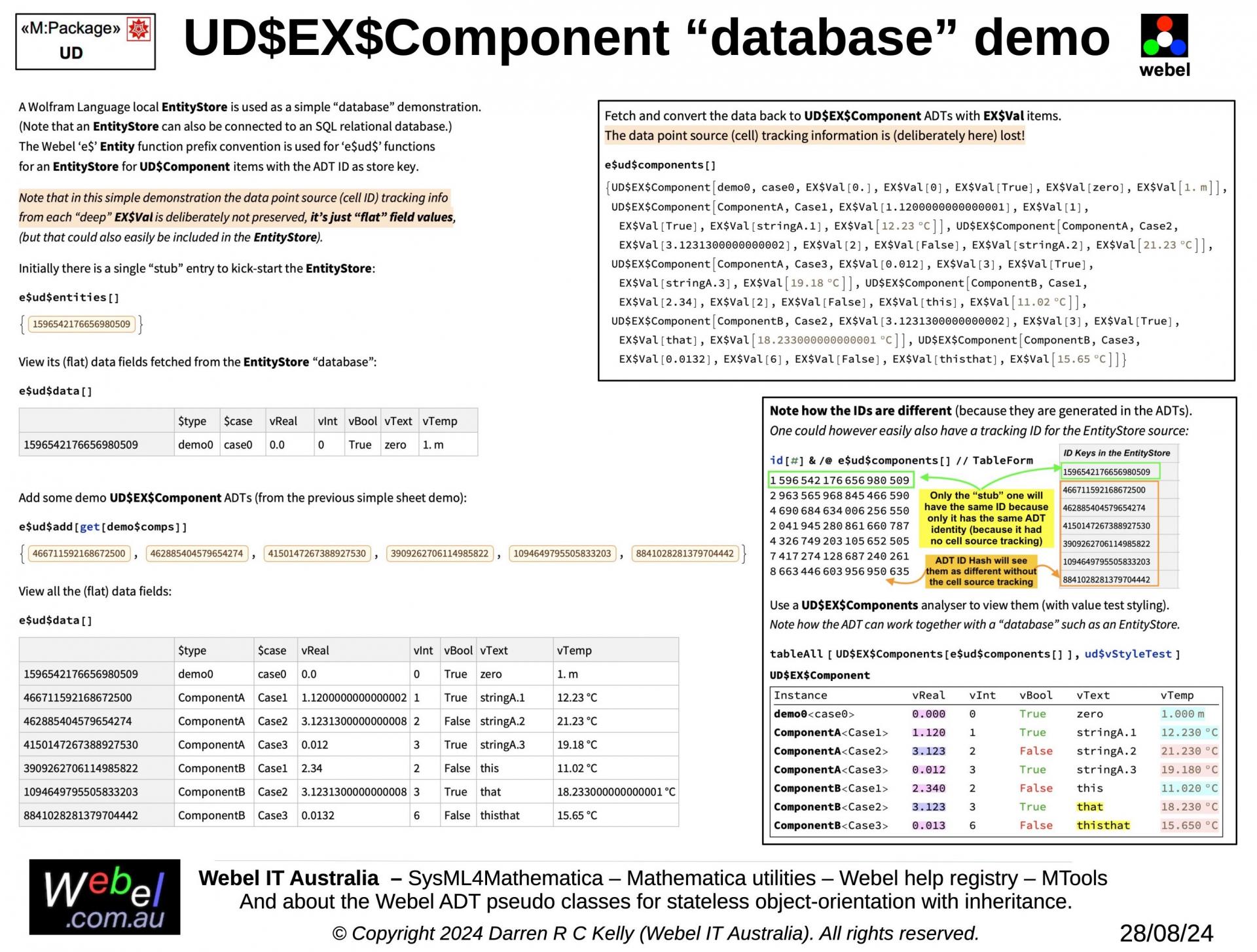
This slide trail section shows selected aspects of an application of the Webel ADT recipe to identification and extraction of structured data from unstructured spreadsheet data in the OpenXML file bundle format.
Spreadsheet data is not truly structured data; it may have some rows and columns in sheets, but there is no actual data schema that groups the data according to a specific domain.
For example, in a spreadsheet for engineering test data for a device (an assembly of components), just having String labels on rows that indicate where a test data set for a "component" starts - separated from test data for other components by blank lines - is NOT structured data; there are no true relationships to components, devices, clearly defined data groups, or a data schema.
Webel IT Australia has developed a system for handling identification and extraction of structured data from OpenXML spreadsheet file bundles (or any other unstructured data source) as data groups, which can then be written to database, serialised, or otherwise persisted using any of the powerful data handling mechanisms of Wolfram Mathematica, such as the very convenient Wolfram Cloud.
Webel IT Australia also offers a specialist spreadsheet data migration service using these Webel libraries for OpenXML:
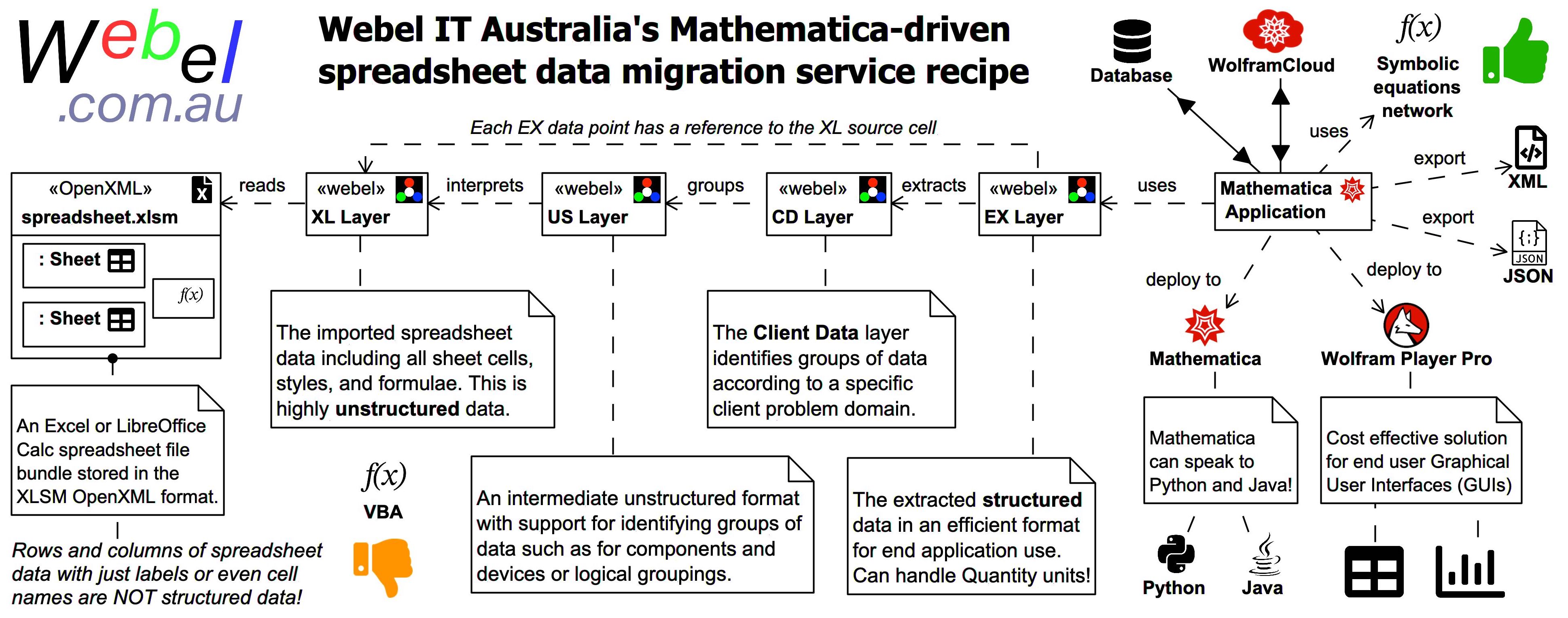
The system has the following main layers, each of which corresponds to a package in the Webel OpenXML libraries for the Wolfram Language:
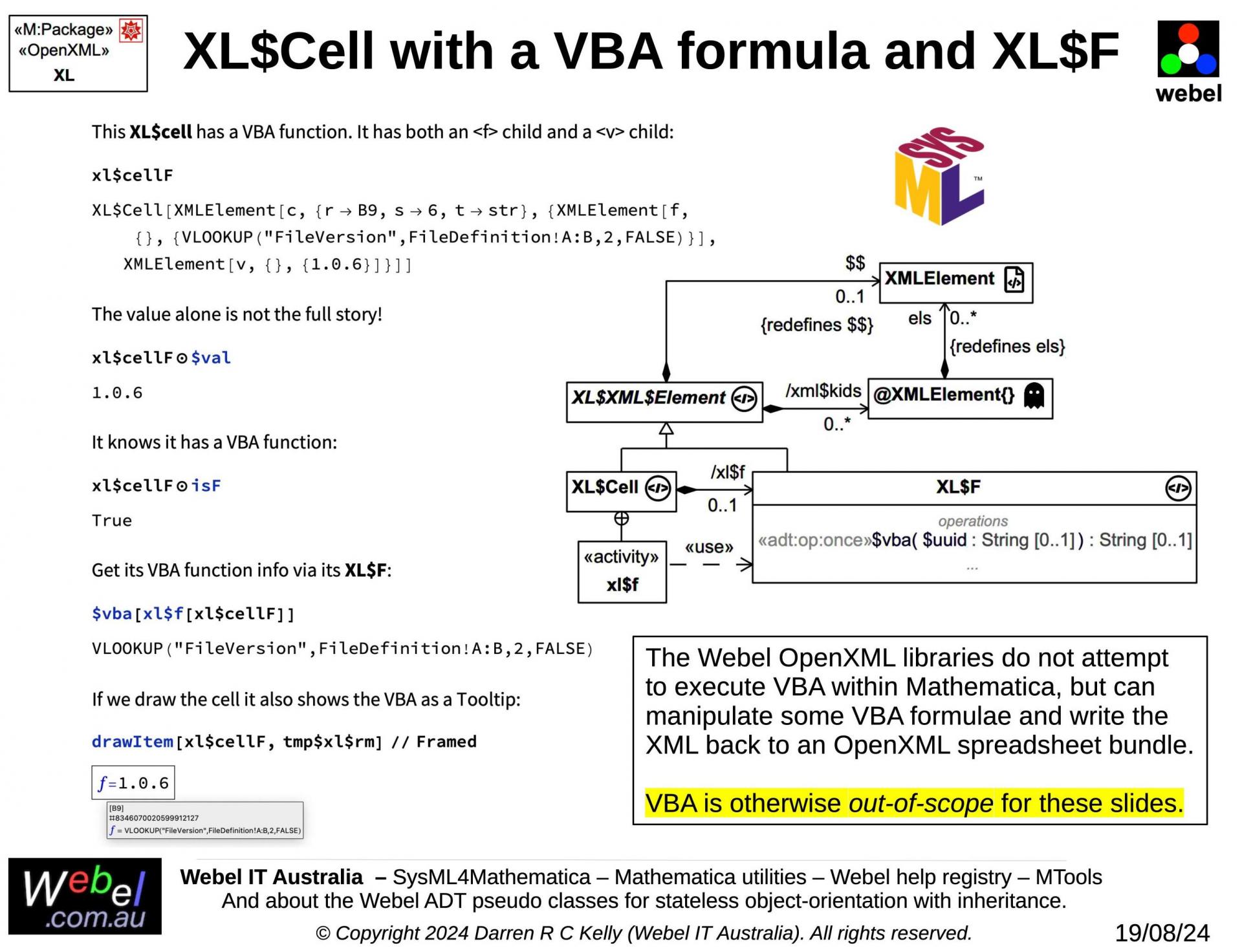
- XL: Spreadsheet data is read from XLSM spreadsheet file bundles, which is a very common file format for Excel and LibreOffice Calc. Under the hood the XLSM bundle uses a number of files in the Open XML format to represent all sheets in a spreadsheet and all other aspects of the spreadsheet. Unlike some spreadsheet reading systems, the Webel system captures not just the data, but all of the information in the spreadsheet, including also styles and formulae. At this stage the data is still just unstructured data accompanied by some style information and metadata. The XL data format can by displayed in Mathematica in spreadsheet similar format, optionally including representation of the imported cell styles, and even showing all of the original spreadsheet cell information as tooltips.
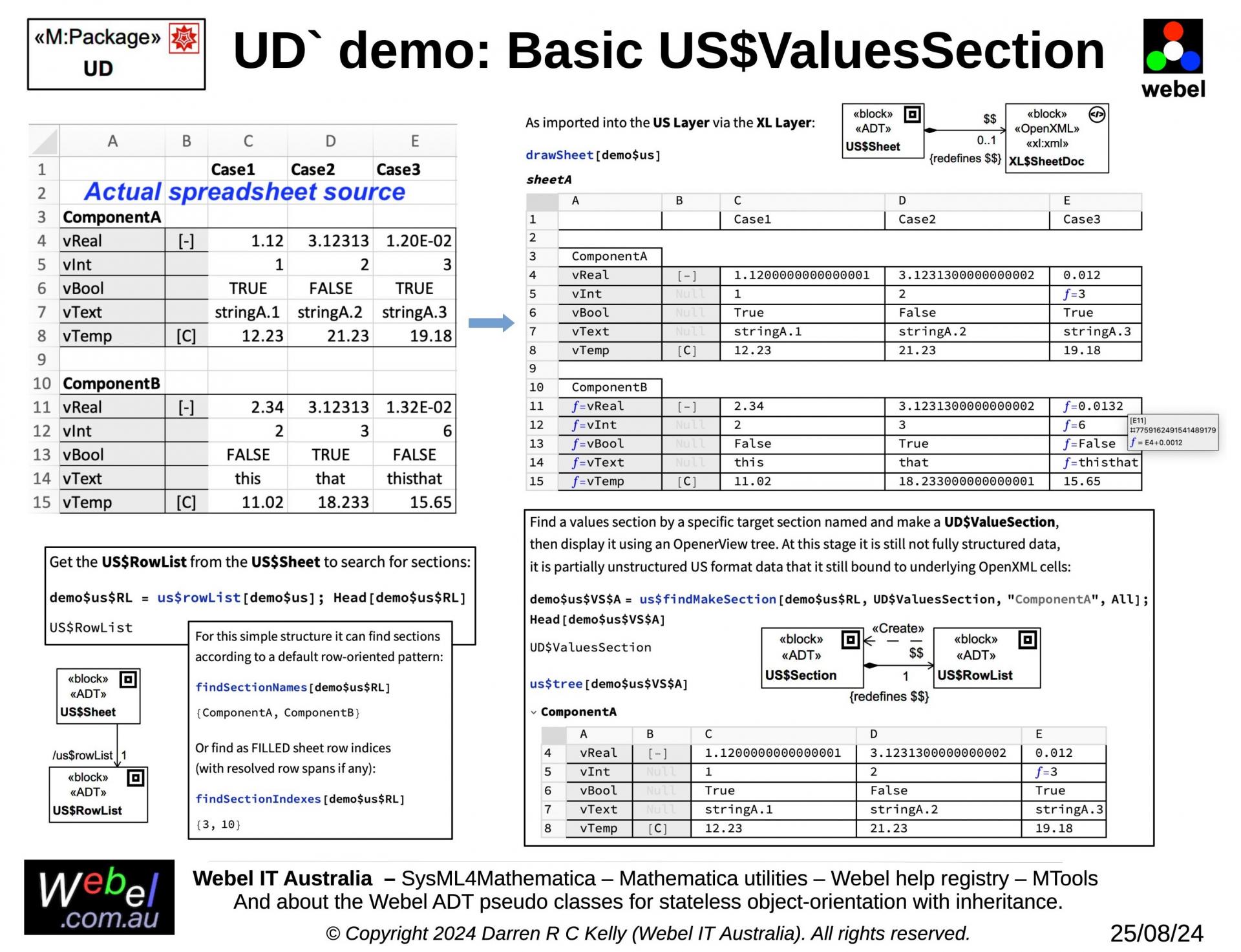
- US: The imported spreadsheet information is then translated to a special intermediate unstructured data layer, still with access to all of the additional styling and underlying spreadsheet metadata and VBA formula used, but not yet with any structured interpretation of the data. This intermediate format has support for flexible identification of groups of data that are candidates for identification of component data, device data, and data groups, and can display the data in rich ways far beyond a mere spreadsheet, including interactive trees of identified data groups.
- CD: The application (Client Data) extraction layer. This typically involves development of a custom library specific to the format of a client's particular data. This is where domain data groups such as device data or organisational data become available as structured data using domain specific terminology for each identified grouping. This layer leverages the powers of the Wolfram Language for parsing and identifying patterns in unstructured data!
Note that 'CD' here is not the name of an actual package, it is a placeholder for a specific client's domain packages; in the examples shown here packages from an actual client project are used (but with obfuscated data) with ADTs prefixed by 'EA' representing the Client Data layer.

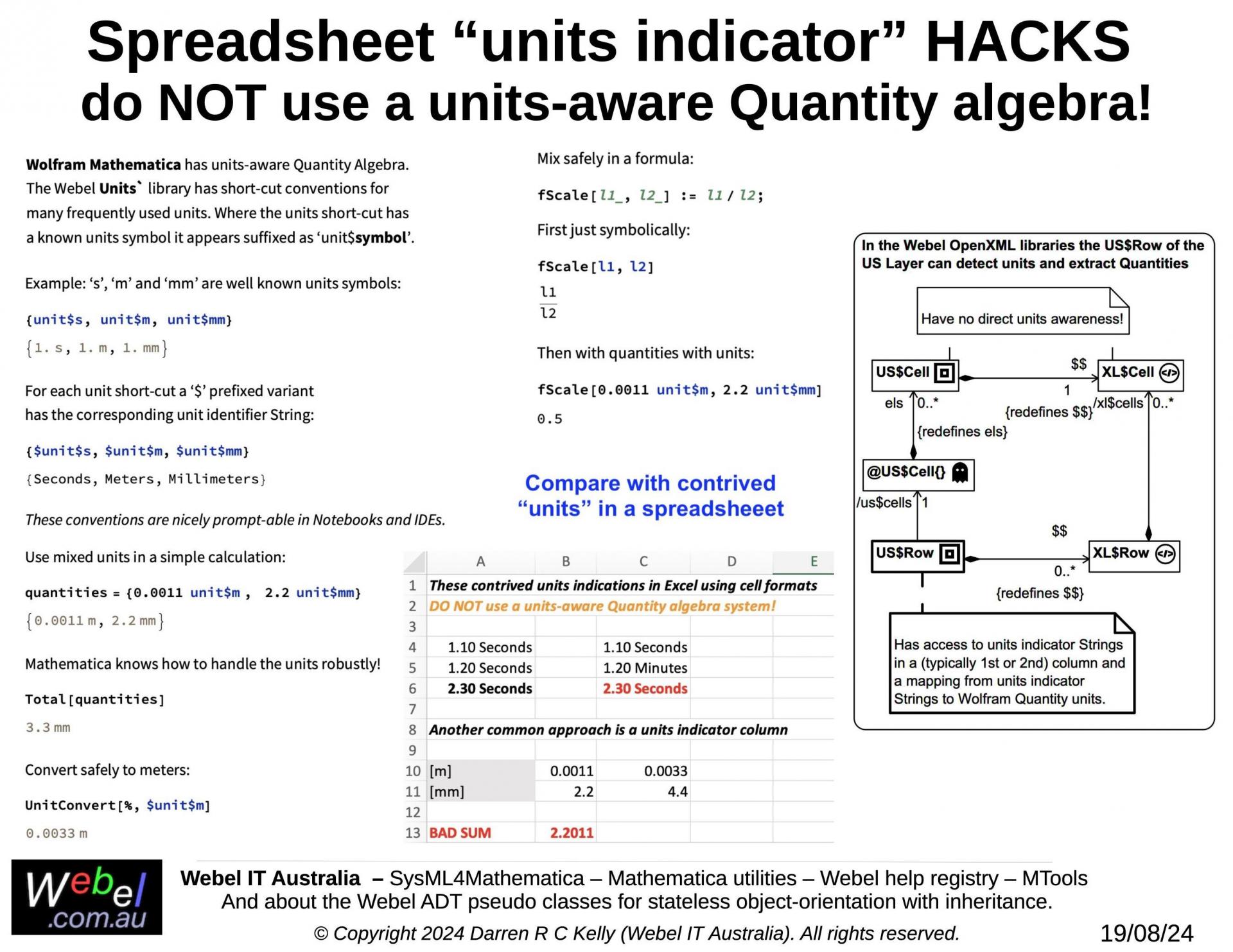
- EX: The extracted data layer. The data is now decoupled from the spreadsheet and encapsulated in a highly structured form, but still keeps a reference to its source (each data point knows which spreadsheet cell it came from). This data does not have the spreadsheet formulae, but can still be traced back to the formula of its ancestor cell. This an efficient format for further use in Mathematica. EX format data can also use units-aware Quantity algebra and numerics! And the Webel system can detect units indicator text labels in the original spreadsheet.
The EX` package has support for some common data structures, and is typically extended with domain-specific Webel ADT pseudo classes.
The extracted data can then be persisted to the Wolfram Cloud or to other cloud databases, or exported using serialisation formats such as XML (against an XML Schema) or JSON. All of the above steps are easily automated into a single workflow, and can be incorporated into an end-user GUI for deployment to Wolfram Player Pro, including powerful Mathematica data analysis and visualisations.
The Webel system also uses the Wolfram Language Once-caching mechanism to enable efficient processing of large spreadsheets and datasets, and has been tested on very complex industrial strength tasks.