
Keywords
CAVEAT: This guide needs some more supporting code examples. For now, this description in text and graphs do already describe the pattern quite well.
Terminology:
- 'client': Refers here to the consumer of a method of a 'supplier' class object (not the nice people who pay consultants to do work for them).
- 'class object': Refers here to an instance of a
class, as opposed to an instance of a low level data type, noting that in Python even int, float, str, etc are objects. (And not to confused with a class created as an "instance of a metaclass".)
In this guide, the term lazy instantiation is preferred over lazy initialisation, because the primary use of the pattern described is for instantiation of new class objects (along with initialisation of their fields).
According to some definitions, instantiation is allocation of memory for a new object, and initialisation is population of the fields with values (execution of the constructor). For the sake of brevity here, lazy instantiation covers both creation and initialisation of a new class object (including use of any arguments passed to the __init__ constructor for initialisation).
The term lazy loading is avoided here, because it covers also strategies such as delayed loading of resources, data sets, images, etc., and delayed web page content loading, which topic is not covered here. It is often contrasted with eager loading.
Finally, many database entity mapping frameworks also permit field loading to be set as lazy or eager. Such database frameworks are completely out-of-scope for this discussion. See however this remark on not replicating in code what database frameworks already do for you robustly and better.
Dr Darren says:
Cascading lazy instantiation (pull lazy pull lazy pull), is your very good friend.
Cascading lazy initialisation (aka lazy instantiation or lazy loading) helps promote a more pure functional approach within lazy zones, helps reduce bad coupling, makes dependencies and the creation cycle clearer, and can be implemented in nearly any language. Including in Python.
Before we look at the Webel Cascading Lazy approach, a quick word on some of the many different ways of implementing lazy initialisation of fields in Python.
Many online articles about lazy initialisation for Python demonstrate the @cached_property decorator approach and/or the @property decorator approach (using the if self._field is None: test). Both of these seem convenient in that one can then just access obj.field on an object.
See the External Links below for examples of the many existing strategies for basic lazy instantiation available in Python, they are not otherwise covered here.
The Webel approach uses method-triggered lazy access only; it does not use field-triggered access, and it deliberately does NOT support setters:
class Lazied:
# Inject anything specific to the usage scenario in the constructor
def __init__(self, arg):
self._arg = arg # NOT LAZY!!!
self._lazy = None # Or "private" self.__lazy
# NO ARGS!
def lazy(self): # Or get_lazy(self)
if self._lazy is None:
# If the lazy depends on self._arg this is where it would be used.
# Populate directly OR via lazy pull on another object (cascading).
self._lazy = ...
return self._lazy
Typically the lazy() returns a class object (or a container type, but wrapping a low level container type such as dict, list, Pandas DataFrame, or NumPy array in a managing class is usually better).
The Webel Cascading Lazy Pattern
lazy() corresponds to a field with the corresponding name _lazy (or __lazy if using "private"). One can alternatively use get_lazy().
Under this approach, families of collaborating lazy classes use a single pattern with the following rules:
- All access to class objects and data containers within a lazy zone is via
lazy()accessor methods (note the parentheses). - There is no direct access by clients to fields (clients must go via the
lazy()accessor). - There are NO setters! Everything any class object needs to do its job must EITHER be injected during construction OR pulled from a
lazy()accessor of an object it has access to – which object itself was either injected or obtained from alazy(). - A
lazy()may not return None (and any mal conditions preventing population of the lazy must be caught and handled). - Even within the same class, another lazy method that relies on a lazy field MUST access it via its lazy method, not via the field (it must use cascading). If the instantiation within
lazy2()depends on 'lazy1' it MUST calllazy1()– not attempt to directly accessself._lazy1.
(There is actually a variation on the pattern where a lazy() may return None, and the onus is on the client to check against the None, but for now we'll stick with the above rules.)
It is a completely uniform strategy within each lazy zone. You know, without exception, that if you hit a lazy() it will resolve. That it is doing so lazily is anathema to the client, but that it is not None is part of the contract.
And that's where the "cascading" part comes in. A lazy() pulls from a lazy() pulls from a lazy() pulls from a lazy() until it resolves to a data source or to injected data or injected parameters provided via the constructor. It is a completely clear and reliable dependency chain with a completely clear lifecycle.
It addresses, for a wide range of programming tasks, a wide number of possible issues, and makes all of your code more robust, clearer, and easier to debug, too.
Note that it is not just a technique for a single method; it is a systems thinking strategy (one that has nothing specifically to do with Python) with completely uniform policies.
It also works well with creation patterns such as Factory, Abstract Factory, and Prototype.
And it's also easy to model graphically in Systems Modeling Language (SysML®) or Unified Modeling Language (UML®), which is a very useful thing to do, and makes explicit the "sinks depend on sources" approach.
But what about parametrised methods requiring arguments?
You'll actually find that, under consistent use of this pattern, a whole heap of methods that would otherwise take arguments simply vanish from your code. Any method that DOES take arguments you'll know is NOT a lazy(), because - under the rules or the pattern - all class object accessors are lazy() and do not take arguments.
Under the pattern, cases you might otherwise use a method with args for are replaced by a "sink" object that takes any required parameters in a constructor. Such classes can often be associated with Use Case scenarios. This approach also makes the code more maintainable, as it helps avoid having classes with lots of methods that don't correspond to a clear class responsibility. And it makes it absolutely clear what each scenario depends on.
If you find, when using the pattern, that your scenario class has a constructor argument list that is uncomfortably long, it's usually telling you that you need to break the scenario down into smaller sub-scenarios (for those of you who know some UML or SysML this is like the Extends and Includes relationships in Use Case Diagrams). You can then inject one or more sub-scenario objects (that have each nicely grouped some driving args) into your top-level scenario constructor, and that whacking great long list of top-level args has been parametrised by sub-scenarios, which is cleaner, better, and easier to maintain.
You can in fact combine lazy instantiation with some methods that do take arguments, such as caching the result for a particular argument, but that's not part of the basic pattern as described here.
What about service methods that take no arguments yet are not accessors?
If you are using the get_lazy() convention instead of the lazy() convention for a field with the corresponding name _lazy this concern does not arise.
In any case, the client usually doesn't care. Consider a close() for, say, a database connection. You might wish to not return anything (a "void"), or you may wish, say, to return True or False depending on whether the attempt was successful (although performing error handling within the close() might be better). Just as long as it does not return None, it still works with the pattern.
What if I'm dealing with data that might be NaN or None?
The pattern is primarily for objects and containers of data, not for low level data. A lazy() for data handling could still return a data container (a data manager class, a Pandas DataFrame, or a low level dict or such) and then one can check for NaN or None elements (you are thereafter outside the scope of the pattern).
However, it's better to have the intelligent data managing class object do the NaN or None elements check for you:
[ASIDE: If you must return a low level data structure such a dict, list, or set, prefer an immutable variant (tuple instead of list, frozenset instead of set, frozendict or immutabledict instead of dict, StaticFrame instead of DataFrame).]
Data format fields and as_ methods
If is often useful to use lazy accessor method names like as_json or as_xml rather than get_json or get_xml. But the mechanism is the same, and there are still _json and _xml fields (
or __json and __xml if you want "private").
Lazy zones
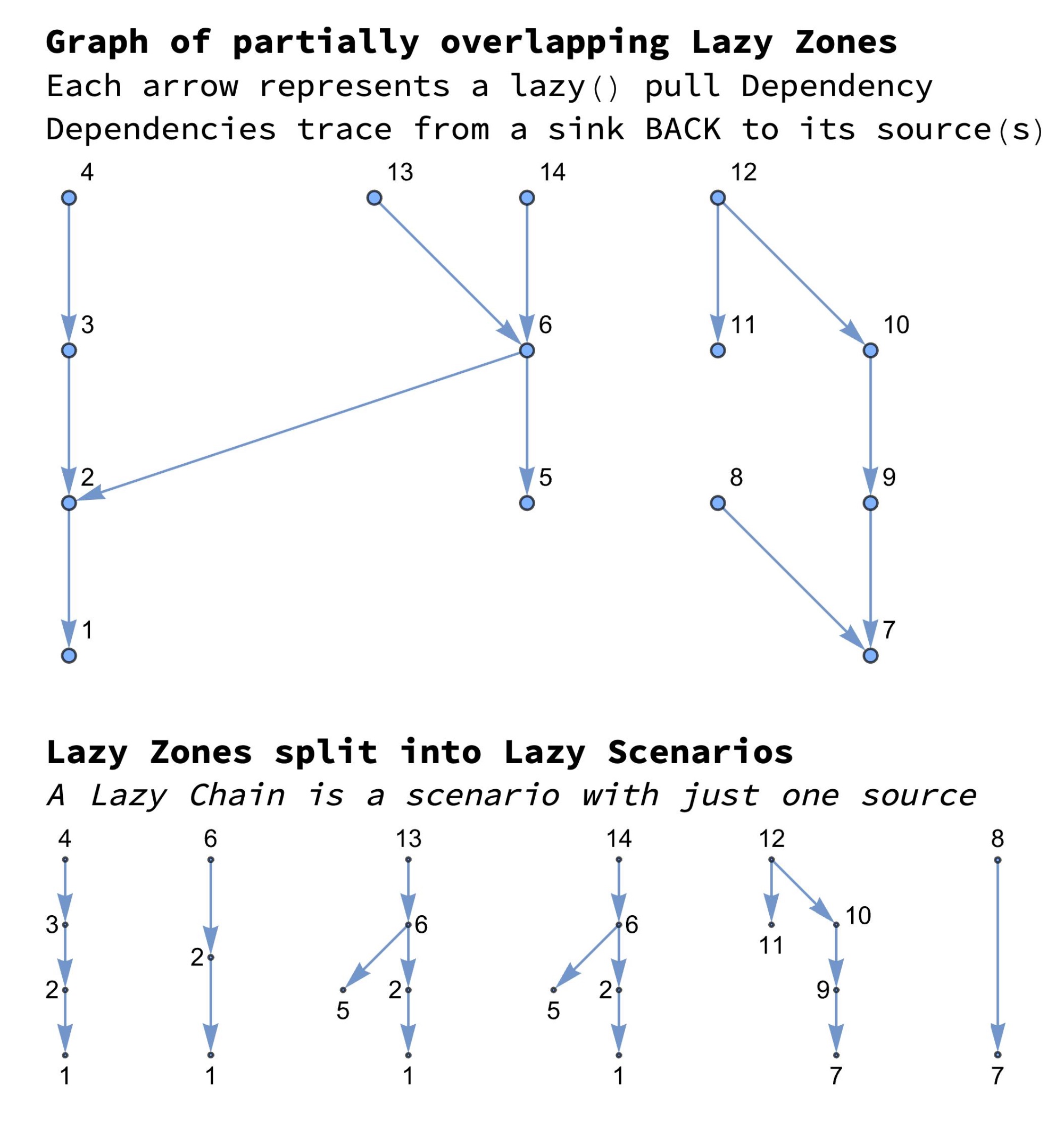
The Webel Cascading Lazy Pattern splits your application up into lazy zones and into other zones not covered by the pattern. The more the degree of coverage by lazy zones, the better:
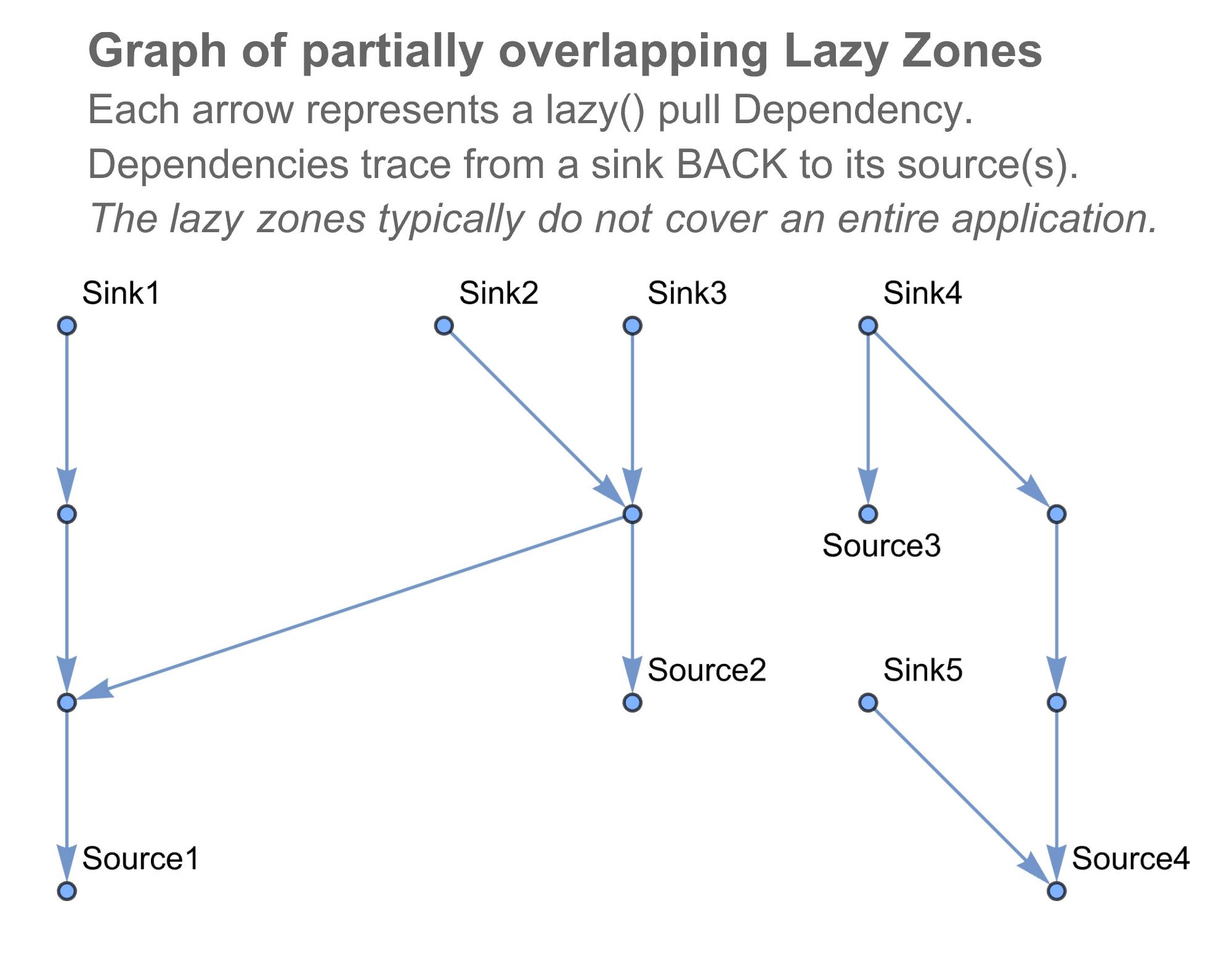
Each lazy zone can be decomposed into one or more lazy scenarios. (A very simple lazy zone only has one lazy scenario). The head of each lazy scenario is a "sink" and the Dependencies go BACKto one or more "sources". A lazy scenario with just one "source" is a lazy chain. Sometimes "sources" are shared by more than one lazy scenario:
For example, reading (pulling) data from a file (typically assumed not to change), parsing the data, and then transforming that data to say JSON or XML would all be within a single lazy zone. A FileToPacket class might be initialised with the filename during construction, and a single lazy as_json() method would perform all operations lazily then hand off the JSON; it would pull lazily from a Parser, which pulls lazily from a FileReader.
If one then performs as_xml() on the same FileToPacket object, nearly everything it needs to offer the XML has already been lazily pulled. Both the as_json() and the as_xml() methods are connecting to a shared lazy chain.
If you suspect the file has changed you can use either cascading reset() first or just create a fresh "sink" object and pull again (repeat a one-shot pull).
Not every part of a typical application can be covered by lazy zones. The aim is to use lazy zones to cover as much of your application as possible. Even use of very fine-grained lazy zones for smaller tasks has benefit.
Resetting lazy scenarios: reset() vs one-shot
You can have a reset() method in lazy classes that resets every lazy field back to None. If you are using cascading lazies you need to cascade each dependency reset(). The cascading reset() percolates back down to the source(s).
reset() won't be seen upstream in other lazy scenarios.
It's simpler (and safer) to instead just create a fresh "sink" object that is the final part of the source-to-sink lazy scenario and have it pull everything fresh again (cleanly repeat a one-shot). The advantage is that you don't need to maintain reset() code, which is a possible point of fragility (it's slightly WET since you have to match the dependency chain logic carefully); if you instead just use the existing lazy() chains they are self-maintaining.
The only slight disadvantage of using a fresh "sink" object is that – in cases where its source(s) were shared by other lazy scenarios – it will create new source objects instead of actually sharing them with those other lazy scenarios. This is usually not a concern, unless it causes, say, unwanted competing database connections (but typically the database connection will have been closed after fetch).
Does the pattern work for everything?
The pattern does not cover every possible programming case, but the more you can code in terms of lazy zones, the better. The pattern has incremental benefit.
The pattern is well suited to any situation where there is transformation of structured data, conversion of structured data, or value-adding processing of structured data.
The pattern is very well suited to combination with Data Access Objects (DAOs).
As regards domain models and entity models, the pattern is more easily leveraged with hierarchically structured data where there are clearly identified groupings. A good example is a data for a Building model that has known building element types such as Floors, Walls, Beams, Columns etc. The lazy for a Building pulls its Floors, Walls, Beams, Columns lazy groups, and each of those lazy groups pulls each Floor, Wall, Beam, Column etc. respectively.
(The pattern is by no means restricted to domain/entity models and is not intended to replicate what is often best handled by an entity synchronising database mapper, the Building example used is just easy to explain.)
For completely dynamic entity modelling without pre-known structures (where classes can't be associated directly with model elements types), the pattern is still useful, but one has to careful not to undermine or directly replicate the dynamic modelling framework itself. Those a little older amongst you might recall Service Data Objects (SDO) for Java. The Eclipse Modeling Framework (EMF) for Java also to some extent counts as a dynamic modelling framework. PyECore offers "A Pythonic Implementation of the Eclipse Modeling Framework".
The pattern is also applicable to parametrised query cases with some adaptation. Consider, for example, a query for all building beams of a particular kind, which one wishes to convert to various formats such as JSON, XML, etc. The query can usually be represented as query parameters offered to a constructor that acts as the head or "sink" of a lazy scenario, and nearly everything thereafter is within a lazy zone (at the "source" the query will typically resolve to a database query using a specific technology).
As explained above, the "sink" object can usually be identified with a Use Case scenario.
Hybrid and partial use of the pattern
Consider again a model of a building. If the model is in database and you just wish to load the model and have various readonly representations of the building data as say JSON or XML, or transformation of the building data (perhaps for hand off to an API end point), the pattern covers it completely.
However, if you wished to manipulate the model of the building live in memory (leaving aside whether or not that's a good idea) the pattern may only partially cover the case, depending on how you wish to implement it.
For the sake of this example, we'll assume we aren't (for better or worse), using an ORM backed database, but something simple like an HDF5 file-based database (as opposed to fully synchronised entities).
Let's say a user wishes to add a new Column to one Floor of a Building. Assume each Floor has Columns. The container object for the Floors and the Columns within each Floor will have already been created, and lazily. The new Floor (perhaps as just a stub or template or perhaps with detailed specification) will typically be created using a creation pattern such as Abstract Factory or Prototype, which step falls outside of the lazy zone, but then might connect again to another lazy scenario.
There are many options for managing the addition of the new Column to the Floor:
For example, in a strict pure functional approach, an entire new updated Building model would be spawned from the original model (which might not be efficient or tenable if a deep copy is initially used, although there are strategies for safe-ish reuse of a shallow copy of those parts of the building that have not changed).
Or one may instead permit the Building model to be changed in-place (the containers for Floors, Columns, Beams would be mutable), and you can simply add the new Column to a Floor.
Either way, the changing of such a hierarchical data structure requires a break at some point from the pattern. But there is still great benefit to be had by having lazy cascading of the creation of the building element containers.
What about persisting changes data back to database? What about user input?
There are other cases that fall outside of a lazy zone. But nearly everything that leads up to those cases can usually be captured as a lazy zone.
Input of user data acts as an input "signal" for a fresh lazy zone, which might, say, transform user data into a form compatible with a particular database (within that lazy zone) and then do the final database persistence "push" (outside the lazy zone).
How can one document a method as a lazy() in Python
If you are using the Webel Cascading Lazy Pattern brutally consistently as intended, it really isn't necessary to document each lazy() or get_lazy() as meeting the pattern, although adding a # lazy comment doesn't hurt.
The get_lazy() naming convention is a bit clearer than just lazy(), and avoids confusion with service methods with no args.
Documenting using docstrings for this purpose is not pretty.
Unlike Java, where one can create custom @annotations, Python does not directly have such a convenient equivalent; a Python @decorator has to implement __call__. It's no drama though to have a Python decorator @lazy that does nothing, and it's clear in the code.
@lazy is also used by some contributed libraries for decorators that offer specific lazy instantiation logic!
For example, there is a project called lazy that uses a @lazy decorator in a different way from the Webel Lazy Cascading Pattern.
You can also use or abuse function attributes in combination with a @decorator that sets a flag, as shown here, although it's a bit hacky.
Debunking a popular myth about lazy instantiation/initialisation
It is sometimes argued that use of lazy instantiation complicates the codebase. What, because of two extra lines of code for each field? Whereas apparently having a heap of field initialisations separated by comments in a huge constructor is easier? And without being able to clearly see what field depends on what other field (or being sure that the field was indeed initialised) ?
Using lazy instantiation provides a clear point of documentation and a place for developer comments to live. You know exactly where it is initialised, you can use that lazy() method in the code to explain anything notable about the particular initialisation. Looking for details of initialisation of a field? Simply go to its lazy().
AND you can also easily trace what else depends on it by checking usages of the lazy() by adopting the Webel cascading approach.
In fact, it's so much cleaner for code organisation, it's still worth doing even if you also choose to trigger each lazy() in advance in the constructor anyway! Which brings us to an indeed genuine possible concern ...
Synchronisation: A genuine possible concern with lazy initialisation
In some languages, under some conditions, for some applications, in multi-threaded environments, one has to ensure that a lazily initialised field is initialised only once. In Java, this can be addressed using synchronized. In Python, it's slightly messier, since you have to the threading module and threading.Lock or threading.RLock. If you are keen you can write your own synchronising decorator.